신약개발과 AI, 펩티드 서열의 벡터화
22개정 인공지능 수학
메디컬저널
메디컬 현업 전문가팀
AI 신약개발의 핵심인 자연어처리(NLP) 원리를 기하 과목의 벡터 내적 개념과 연계하여, Word2Vec(Skip-gram)의 단어 임베딩 학습 과정을 수학적으로 정리하고, 이를 단백질·펩타이드 서열에 적용한 ProtVec 임베딩 기법의 원리와 신약 후보물질 선별에의 활용 가능성에 대해 탐구한 보고서입니다.
✔️ 안녕하세요 의치한약수 메디컬 수시 학종 합격을 위해 반드시 참고해야 하는, 의약계열 학종 세특 심화 탐구보고서 전문 메디컬저널입니다.
22 개정 교육과정, 인공지능 수학

⌙ 현 고1부터 2022 개정 교육과정, 고교 학점제가 시행되었습니다. 과목 구성을 살펴보면 수학 진로선택 과목으로 <인공지능 수학>이 눈에 띄는데요, 기존에 없던 과목이 22 개정 교육과정에 포함된 것은 최근 산업과 경제 전 분야에서 두드러지게 나타나는 인공지능의 영향력과 인공지능을 정확히 이해하고 활용하는 것의 중요성이 반영된 것으로 이해할 수 있습니다.
신약개발에서의 AI의 활용
제약바이오, AI 신약개발 박차…"패러다임 바뀐다" | 약사공론
제약업계가 인공지능(AI)을 활용한 신약 개발에 본격적으로 나서며 연구·개발(R&D) 효율화와 글로벌 시장 진출을 목표로 하고 있다. AI 기술이 신약 개발의 시간과 비용을 획기적으로 단축시킬 수 있다는 점에서 업…

“기간·비용 절반 이하로”… AI 신약 개발에 사활 건 K바이오
기간·비용 절반 이하로 AI 신약 개발에 사활 건 K바이오 국내외 제약사들 AI 플랫폼 개발
⌙ 위 기사들의 내용과 같이, 최근 국내외 제약사들은 신약개발에 AI를 적극 활용하고 있습니다. AI를 활용하면 기존의 신약개발 과정에서 소요되는 기간과 비용을 절반 가까이 단축시킬 수 있을 것으로 기대되며, AI를 활용한 신약개발 시장은 2028년 약 7조원까지 성장할 것으로 예상되고 있습니다 (리서치 앤드 마케츠)

⌙ 정부(식약처)에서는 <의약품 개발 시 인공지능(AI) 활용 안내서>를 발간할 만큼, 정부와 산업계 모두 AI 활용 신약 개발을 핵심 첨단 산업으로 육성, 투자하려는 움직임을 보이고 있습니다.
⌙ AI는 신약개발 과정 중 후보물질 발굴과 임상/비임상 시험 결과 분석 등 신약개발의 전체 과정에서 활용될 것으로 예상되며 정부와 산업계 그리고 학계까지 관심이 집중된 분야인 만큼, 의약계열을 진로로 희망하는 학생으로서 이에 대해 관심과 경쟁력을 세특에 담아내는 것은 긍정적인 반응과 평가를 이끌어 낼 수 있을 것으로 기대됩니다.
데이터를 표현하는 수학적 도구, 벡터와 행렬
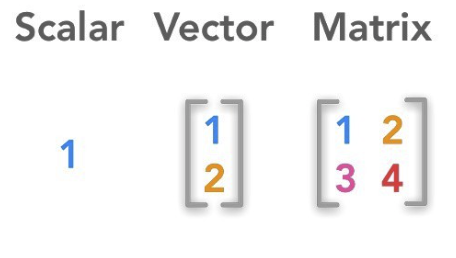

⌙ 스칼라와 벡터의 비교는 통합과학과 물리 과목에서 아마 들어본 적이 있으실 것으로 생각됩니다. ✓ 스칼라는 단순히 하나의 값으로 방향을 가지지 않고 크기만을 가지는 물리량 입니다. 반면 크기와 방향을 가지는 물리량으로 배웠던 ✓ 벡터는 여러 차원으로 표현되며 스칼라보다 더 많은 데이터, 정보를 나타낼 수 있습니다. 고등수학 기하과목에서 배우는 벡터는 주로 2차원, 3차원 공간에서 표현되지만, 그보다 차원을 더욱 늘려서 더 많은 정보를 포함할 수 있습니다. 예를 들어 (a,b,c,d,e)는 5차원의 벡터입니다.


⌙ 행렬은 가로 줄인 행(row)과 세로 줄인 열(column)로 구성되며 m개의 행과 n개의 열을 가진 행렬을 m x n 행렬이라 합니다. 위 그림의 박스와 같이 행이 1개 또는 열이 1개인 행렬은 벡터가 되며, 행이 1개인 벡터를 행 벡터, 열이 1개인 벡터를 열 벡터라고도 합니다.
⌙ 이처럼 벡터는 특수한 형태의 행렬 혹은 행렬의 일부라 할 수 있으며 따라서 일반적으로 행렬에는 벡터보다 더 많은 데이터가 포함될 수 있습니다. 그러한 이유로 행렬은 특히나 많은 데이터를 저장하고 처리하는데 유용하며, 많은 데이터로 대상을 더 잘 표현할 수 있다는 장점이 있습니다. 그러나 표현해야 할 값들이 많지 않은 상황에서 행렬을 통해 데이터를 표현하는 경우 빈 공간(0)이 다수 발생할 수 있으며 이는 컴퓨터로 처리할 때 메모리의 공간적 낭비를 유발하게 됩니다. (이러한 행렬을 희소 행렬(sparse matrix)이라 합니다)

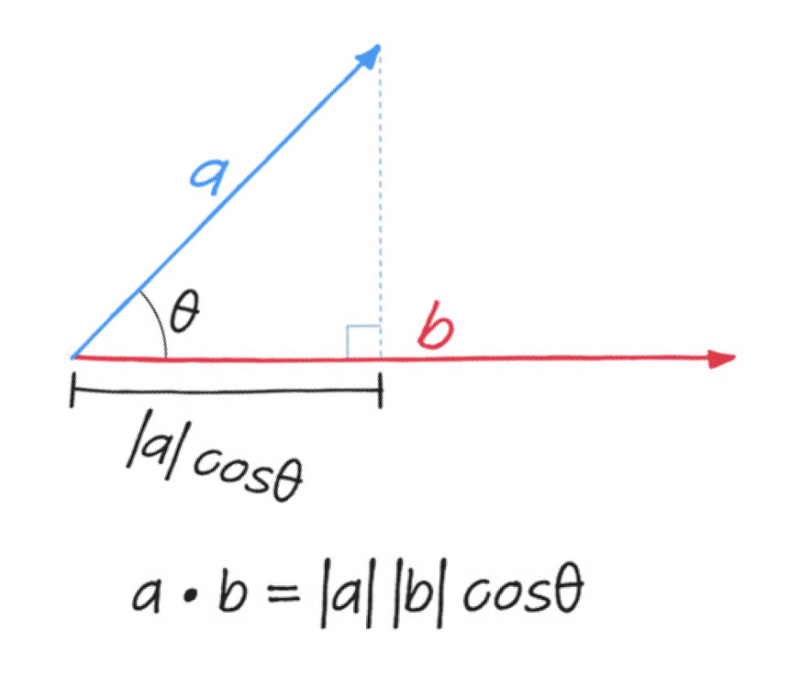
⌙ 기하 과목에서는 두 벡터의 내적이 두 벡터의 크기의 곱에 두 벡터 사이 각도의 코사인 값을 곱한 것으로 배웠습니다.
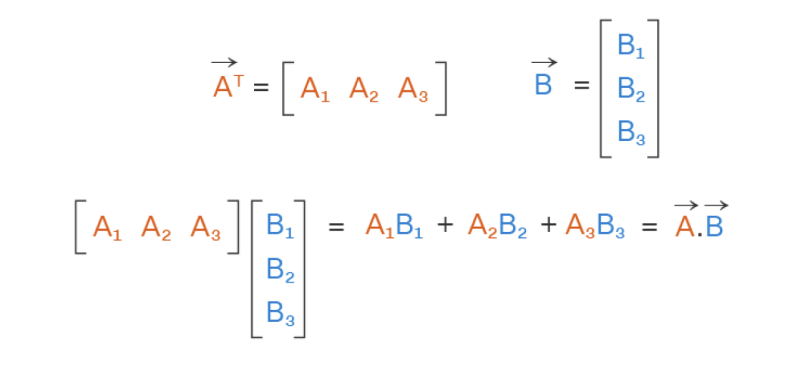
⌙ 위 방법과 다른, 벡터의 내적의 또 다른 방법으로는 하나의 벡터를 행벡터로, 다른 벡터를 열벡터로 놓고 각각 가로, 세로의 순서대로 하나의 성분씩 곱해 더하는 방식이 있습니다. 실제 계산을 해보면 위 방식과 동일한 결과값이 나오게 됨을 확인하실 수 있습니다.

⌙ 앞서 설명한 것처럼, 행벡터 혹은 열벡터가 여러개 쌓인 것이 바로 행렬입니다. 따라서 행렬의 곱셈 혹은 벡터와 행렬 사이의 곱셈 역시 위 벡터의 내적과 동일한 방식으로 계산할 수 있습니다. 위 그림과 같이 2x2 행렬인 행렬A와 행렬B사이의 곱셈은 A행렬 행벡터와 B행렬 열벡터의 내적 4회에 의해 구해지며, 그 결과 2x2행렬이 만들어집니다. 1 x N 벡터(행벡터)와 N x M 행렬 사이의 곱은 1 x M 벡터(행벡터)가 됩니다. 이러한 행렬의 곱셈은 마찬가지로 행렬의 내적으로도 정의됩니다.

❗️우리는 이번 탐구에서 AI 학습을 위해, 우리가 일상적으로 사용하는 언어인 자연어를 컴퓨터가 이해하고 처리할 수 있도록 하는 '자연어 처리(NLP)' 기술에 대해 다룰 것입니다. 앞서 정리한 수학적 도구 행렬과 벡터의 개념 그리고 그 내적 계산이 어떻게 활용되는지에 대해 탐구해보도록 하겠습니다.
아미노산의 종류와 단백질의 구조(통합과학)

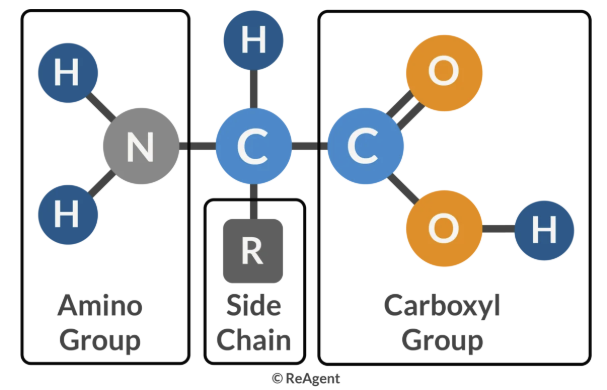

⌙ 단백질을 구성하는 기본단위인 아미노산은 중심탄소에 아미노기와 카복실기 그리고 곁사슬이 결합한 구조를 가지며, 곁사슬의 종류에 따라 20종의 표준 아미노산으로 분류됩니다.
⌙ 아미노산의 곁사슬은 아미노산의 종류를 결정하는 동시에 아미노산의 물리화학적 특성을 결정하게 됩니다. 곁사슬에 의해 결정되는 대표적인 물리화학적 특성으로는 친수성/소수성, 극성, 전하, 산성/염기성이 있습니다. 또한 아미노산이 결합하여 펩타이드, 단백질을 구성하므로 펩타이드와 단백질의 물리화학적 특성은 아미노산에 의해 결정됩니다.


① 1차 구조 : 아미노산이 펩타이드결합에 의해 연결된 1차원적 선형 사슬 구조, 선형 서열를 의미
② 2차 구조 : α-helix(나선형 구조), β-sheet(병렬, 평면 구조) 등 국소적으로 나타나는 구조
③ 3차 구조 : 하나의 사슬이 입체적으로 어떻게 접히는 지를 의미하며, 단백질의 기능을 결정
④ 4차 구조 : 헤모글로빈과 같이 두 개 이상의 폴리펩타이드가 하나의 단위로 기능하는 구조
⌙ 단백질의 1-4차구조는 위와 같이 정리할 수 있습니다. 중요한 점은, 아미노산의 종류와 서열이 2, 3, 4차구조에도 결정적인 영향을 미친다는 것입니다. 예를 들어 2차 구조인 α-helix 부위에서는 사이즈가 작은 아미노산 알라닌(Ala)이 주로 발견되는 특징이 있습니다. 입체적으로 접히는 3차구조 역시 아미노산의 종류와 서열이 직접적인 영향을 미치게 됩니다.
❗️정리하자면, 아미노산의 종류와 서열은 펩타이드, 단백질의 물리화학적 특성을 결정지을 뿐만 아니라, 그 구조와 기능에도 직접적인 영향을 미칩니다. 이는 아미노산의 조합을 통해 특정 펩타이드나 단백질의 특성, 구조, 기능을 분석할 수 있을 뿐 아니라,
⭐️ 아직 밝혀지지 않은 미지 서열의 펩타이드 혹은 단백질에 대해서도 그 조성과 서열만으로 물리화학적 특성이나 구조적 형태, 생물학적 기능을 예측할 수 있다는 가능성을 제시하며, 이러한 예측 과정에 인공지능이 매우 효과적으로 활용될 수 있음을 예상해볼 수 있습니다.
인코딩 vs 임베딩 (인공지능 수학)

⌙ 인코딩과 임베딩은 모두 데이터를 다른 형식으로 변환하는 과정이며, AI 학습을 위해 컴퓨터가 이해할 수 있는 언어로 변환하는 NLP(자연어 처리)에 사용되는 방식입니다.
① 인코딩 (Encoding)
⌙ 인코딩은 주어진 정보를 특정한 형식, 주로 컴퓨터가 이해할 수 있는 숫자 또는 벡터로 단순 변환하는 것을 의미합니다.
# 정수 인코딩
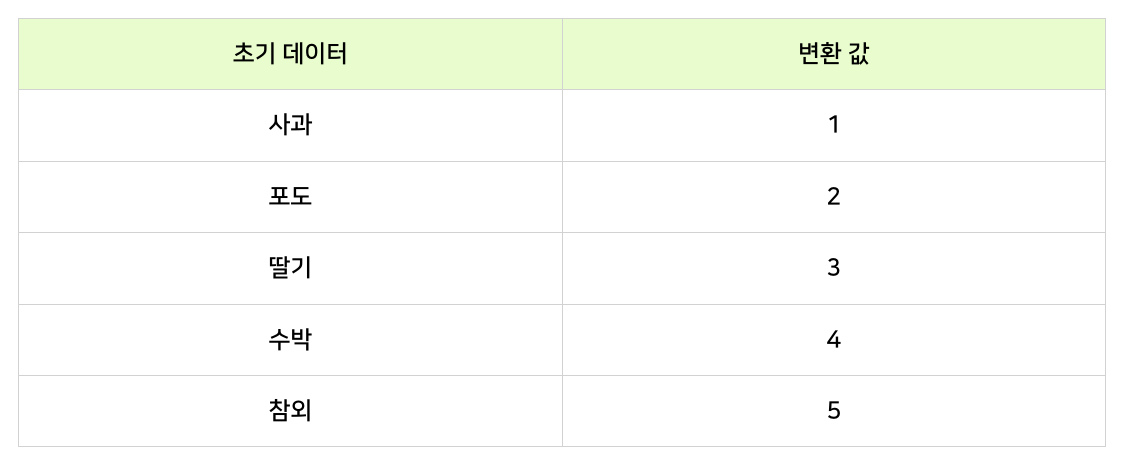
⌙ 예를 들어, 우리가 가지고있는 초기 데이터가 '사과, 포도, 딸기, 수박, 참외'라고 할때 이러한 데이터는 다섯가지의 카테고리(category=범주)를 가지는 범주형 데이터라 합니다. 정수 인코딩은 주로 범주형 데이터를 각각에 대응하는 숫자(정수) 값으로 변환하는 것을 의미합니다.
포도 수박 참외 사과 딸기는 ⇢ 2 4 5 1 3 으로 인코딩(변환)되며, 컴퓨터는 이렇게 숫자로 변환된 데이터를 이해하고 처리할 수 있습니다.
# 원-핫 인코딩 (One-hot Encoding)
⌙ 원-핫 인코딩은 인코딩 방식 중 실제로 가장 널리 쓰이는 인코딩 방식입니다. 앞서 살펴본 정수 인코딩 방식은 각각의 데이터에 서로 다른 정수를 할당하는데 이때 정수의 연속성이 잘못된 의미를 부여할 수 있다는 단점이 있습니다.
예를 들어 2로 변환되는 포도는 순서적으로 각각 1과 3에 해당하는 사과와 딸기의 중간 정도의 의미를 가지는 것으로, 혹은 4로 변환되는 수박은 2로 변환되는 포도의 2배 크거나 혹은 우선순위가 더 높은 것으로 오해할 여지가 있습니다. 즉 정수의 연속성으로 인해 무작위로 변환된 데이터 사이에 어떤(순서나 크기와 같은) 관계가 있다고 컴퓨터가 오해하게 되는 것입니다.

⌙ 위와 같은 문제점을 해결하는 인코딩 방식이 원-핫 인코딩입니다. 원-핫 인코딩은 각각의 데이터를 고유한 행벡터로서 변환하는데, 해당 데이터의 항목과 일치하는 위치에만 1의 값을, 나머지 위치에는 0의 값을 가지도록 이진법으로서 벡터로 나타내는 방식을 의미합니다. 원-핫 인코딩 방식은 각 단어가 특정 위치에 대응되므로 사람이 보고 이해하기 쉽고 직관적이라는 장점이 있습니다.
위 그림과 같이 the, cat, sat 이라는 세가지 단어의 데이터가 있을 때, 각각의 데이터는 그와 일치하는 위치에만 1의 값을 가지고, 나머지 위치는 0으로 채워지는 벡터로서 변환되는 것입니다. 많은 데이터를 원-핫 인코딩으로 변환하게 되면 차원이 커짐에 따라 위 그림과 같이 의미없는 수인 0이 굉장히 많이 등장하게 되는데 이러한 특성을 'sparse(희소)'하다고 표현합니다.
② 임베딩 (Embedding)
⌙ 여러 데이터들을 원-핫 인코딩 방식으로 변환하면 여러개의 행벡터가 아래로 쌓인 행렬의 모습이 되며, 앞서 설명한 것 처럼 의미없는 0으로 채워져 매우 희소(sparse)한 형태가 되며 또한 차원이 매우 크다는 특징이 있습니다. 이러한 형태는 컴퓨터의 메모리 사용을 비효율적으로 하며 학습 성능이 떨어지는 한계점(시간과 비용 문제)이 있습니다.
❗️위와 같은 한계점을 극복하는 데이터 변환의 방식이 임베딩(Embedding)입니다. 임베딩은 변환 과정에서 데이터의 특징 손실을 최소화 하면서도 고차원의 데이터를 저차원 벡터의 공간으로 차원을 축소시킨다는 차이가 있습니다.
✏️ 쉬운 예시로 먼저 이해해보도록 하겠습니다.
⌙ 과일이 총 100종이 있다고 가정합시다. 그 중에서 데이터 항목인 '귤', '사과', '오렌지'를 각각 변환해보도록 하겠습니다.
#1 원-핫 인코딩
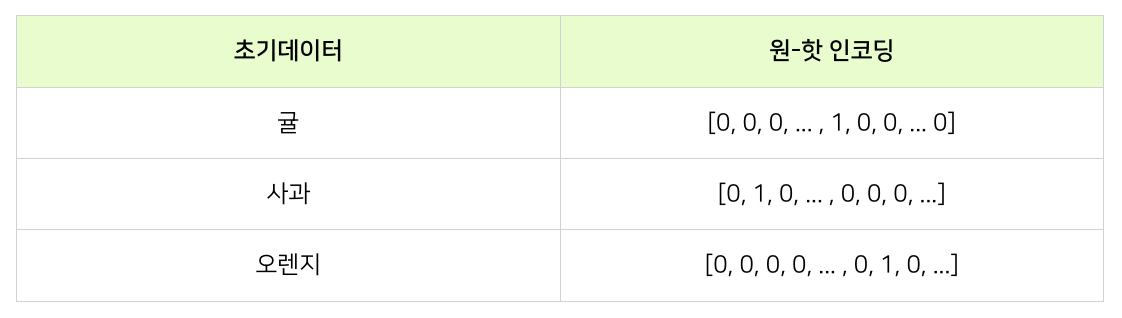
⌙ 원-핫 인코딩에 따르면 귤, 사과, 오렌지는 각각 일치하는 위치에 1, 나머지 위치에 0이 채워지는 벡터로 표현이 됩니다. 각 변환 벡터는 총 과일 수에 해당하는 100개의 차원으로 표현됩니다(99개의 0과 1개의 1)
# 2 임베딩
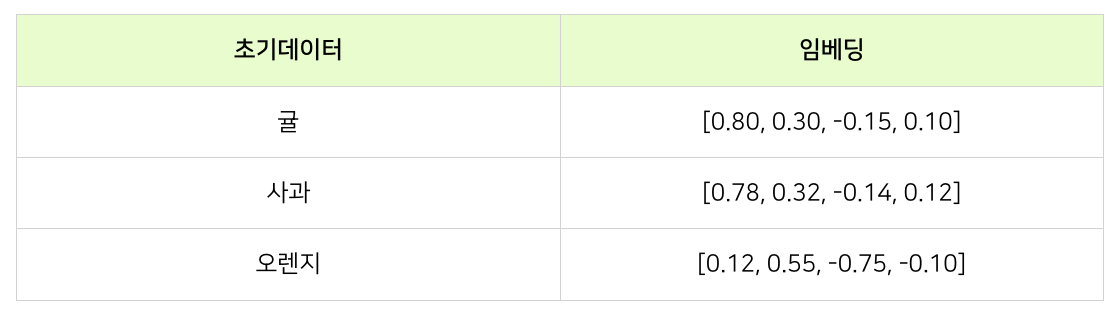
⌙ 100차원으로 나타났던 원-핫 인코딩과는 달리 임베딩으로 변환한 경우 4차원의 벡터로 데이터가 변환될 수 있습니다. (위 변환은 이해를 돕기 위한 예시입니다. 임베딩의 핵심 원리에 대해서는 진로연계에서 살펴보도록 하겠습니다.)
❗️위와 같이 차원을 축소하여 dense(밀집)하게 데이터를 변환하는 장점 외에도 임베딩 방식은 변환된 벡터가 초기 데이터 사이의 유사성과 관계를 반영한다는 차이가 있습니다. 즉, 유사한 데이터는 임베딩 결과 벡터 공간에서 서로 가깝게 위치하게 됩니다. ⇢ 위 예시에서 귤과 오렌지는 큰 유사성을 가지는 과일이라 할 수 있으며 따라서 임베딩 결과 귤과 오렌지를 변환한 벡터는 서로 유사하게(벡터 공간에서 가깝게) 나타나게 됩니다.
단어의 벡터화, 구글의 Word2Vec

✔️ 이제 우리는 본격적으로 자연어처리(NLP)의 원리에 대해 이해해보도록 하겠습니다. 해당 개념은 고등학생들에게 당연히 어려울테지만, 메디컬저널에서 어떤 자료들보다도 쉽게 설명할테니 차근차근 따라오시면 좋을듯합니다 👍🏻
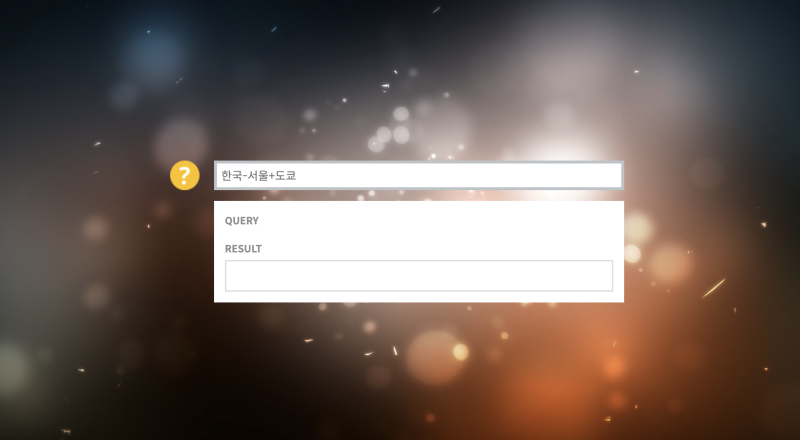
Korean Word2Vec
word2vec.kr
⌙ 위 사이트에서 '한국-서울+도쿄'를 입력하면 결과(RESULT)로 일본이 출력됩니다. 위 예시에서 어떤 느낌이 오시나요? 직관적으로는 단어를 의미를 기준으로 더하고 뺀 것으로 보이는데요, 한국에서 서울을 빼면, '국가'라는 의미가 남을 것이고 거기에 '도쿄'를 더하면 일본(도쿄를 수도로 하는 국가)이 출력 되는 것으로 이해할 수 있습니다.
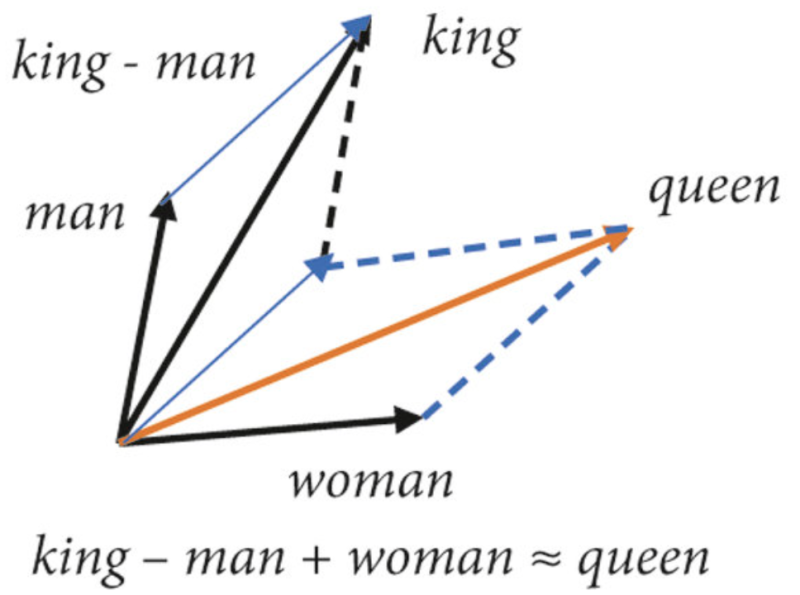
⌙ 또 다른 예시로, 위 그림과 같이 king, man, woman, queen 단어들 사이의 수식을 들 수 있습니다. king에서 man을 빼고 woman을 더하는 의미적 계산을 통하여 queen이 도출되는 것을 이해하실 수 있습니다.
❗️ 그런데, 단어가 숫자도 아니고 이러한 사칙연산이 어떻게 가능한 것일까요? 위 사이트와 예시는 구글이 개발한 임베딩 기법 Word2Vec에 기반한 것입니다. Word2Vec은 그 이름처럼 단어(Word)를 벡터(Vec)로 임베딩(데이터 변환)하는 기법입니다. 즉 한국, 서울, 도쿄, 일본이라는 단어들은 각각 Word2Vec에 의해 벡터로 변환되는데요 Word2Vec은 단어들 사이의 문맥적 관계를 바탕으로 의미적 유사성을 반영해 벡터로 임베딩합니다.
① 의미적 유사성을 반영하고 있다는 것은, 유사한 의미의 단어는 벡터 공간에서 서로 가까운 위치에 놓이게 된다는 것을 의미하며, ② 의미를 기반으로 벡터화 되었고 벡터는 덧셈과 뺄셈이 가능하기에 한국-서울+도쿄=일본의 결과는 의미를 반영한 벡터의 수학적 계산 과정이라 할 수 있습니다.
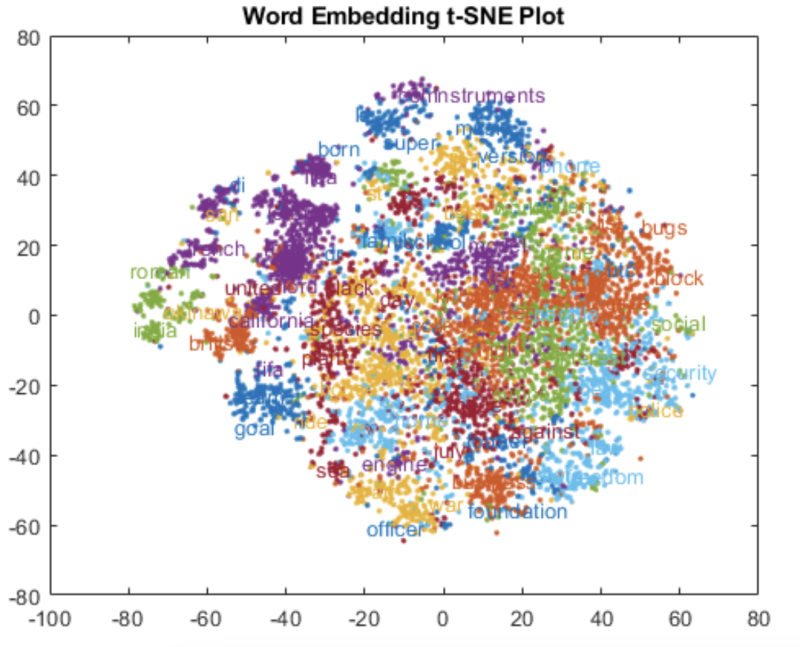
⌙ 우리는 2차원, 3차원의 벡터를 좌표공간 내에서 표현할 수 있지만, 임베딩에서 만들어지는 고차원 벡터 (EX. (a, b, c, d, e, f, g, ...))는 시각적으로 표현하기 어렵습니다.
그러한 고차원 벡터를 벡터들 사이의 거리와 구조를 유지한채 2D 공간에 시각적으로 표현해주는 방법인 t-SNE plot (그 원리에 대해서는 분량의 한계로 이번 탐구에서는 생략하도록 하겠습니다.)에서는 위 그림과 같이 유사한 의미의 단어 벡터들이 군집을 이루며 가까이 위치한 것을 확인할 수 있습니다.
백터의 내적과 Word2Vec의 원리

⌙ 이제 본격적으로 Word2Vec의 원리에 대해 정리해보겠습니다. 단어가 벡터로 변환되는 것은 어떤 원리에 의한 것일까요?

‣ Word2Vec은 분포 가설(distributional hypothesis) 이론에 기반하고 있습니다. 분포 가설이란 비슷한 의미를 지닌 단어는 주변의 단어 분포도 비슷하다라는 가설입니다.
‣ Word2Vec은 머신러닝 방식 중 비지도학습 방식을 사용하여 단어 벡터를 임베딩합니다. 비지도학습이란, labeling 되어있지 않은 데이터들을 학습하여 데이터의 패턴, 특성, 구조를 스스로 파악하는 방식을 의미하는데요 쉽게 말하자면 정답을 알려주지 않고 제공된 수많은 문장들에서 문맥 내 단어들의 관계를 학습하는 방식을 의미합니다.
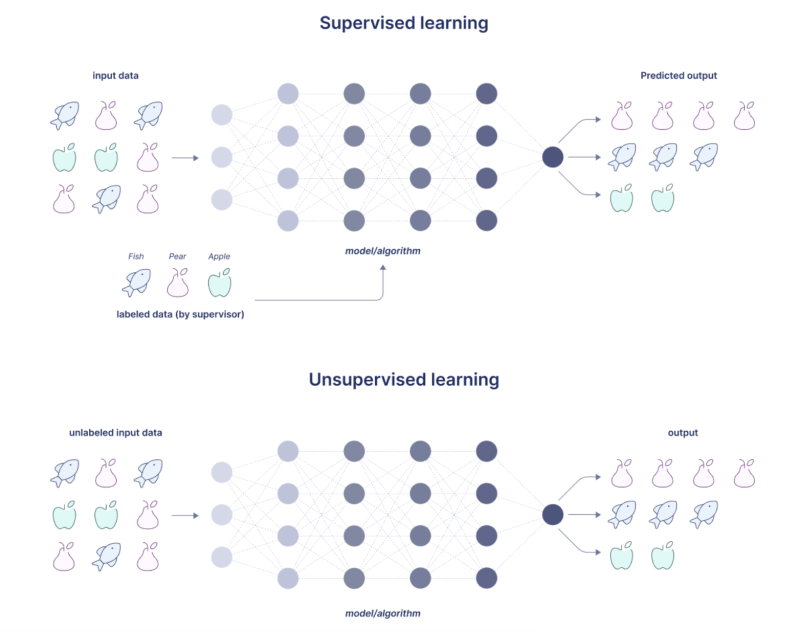
⌙ 지도학습 (Supervised learning)은 위 그림과 같이, "자 이게 물고기고, 이게 배고, 이게 사과야" 즉 정답을 미리 알려준 후 학습하도록 하고 "초록색이고 잎이 달린건 무엇이게?" 에 대한 정답을 예측하도록 하는 방식인 반면,
⌙ 비지도학습(Unsupervised learning)이란 사전에 정답에 대해 알려주지 않고, 스스로 학습을 통하여 유사한 속성을 가진 데이터끼리 그룹화하는 방식을 의미합니다.예를들어, 잎이 있고, 색이 초록색이고 꼭지가 달린 데이터들(사과)을 하나의 그룹으로 묶어내는 것입니다.

✔️ Word2Vec은 가장 먼저 학습을 위한 수많은 문서, 문장, 텍스트 등 데이터셋이 필요합니다. 그러한 방대한 데이터셋을 말뭉치(corpus)라 하며 주로 뉴스 기사나 위키피디아, 웹페이지, 도서 등이 학습을 위한 데이터셋으로 활용됩니다.
❗️Word2Vec의 기본 원리에 대해 다시 한번 정리하자면, 학습하는 문장들에서 주변에 자주 함께 등장하는 단어들의 패턴을 통계적으로 학습하여, 의미 기반의 벡터 공간에 각 단어들을 배치하는 기법입니다. 즉 자주 함께 사용되는 단어들이 유사한(거리가 가까운) 벡터로 변환되는 것입니다.
https://medium.com/analytics-vidhya/word2vector-using-gensim-e055d35f1cb4
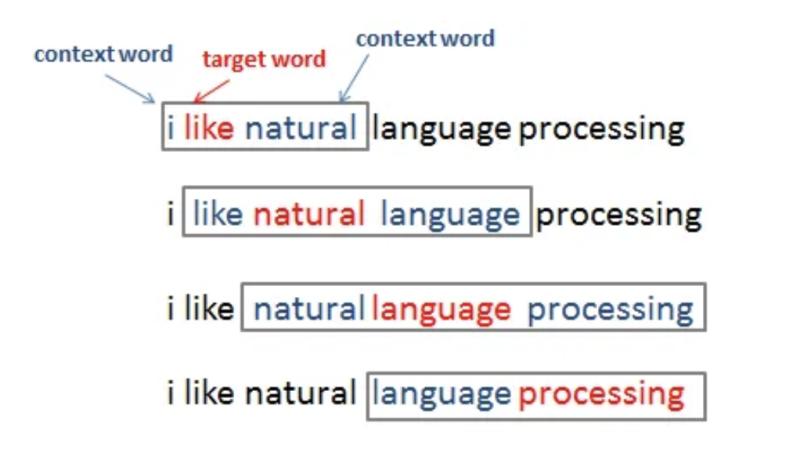
⌙ Word2Vec은 임베딩 과정에서 수많은 문장들을 학습하는데요, 우선 하나의 문장을 놓고 어떻게 학습이 이루어지는지 살펴보겠습니다. Word2Vec의 기본 콘셉은 문장에서 중심 단어(타겟 단어)와 주변 단어(문맥) 사이의 관계를 학습하는 것인데요, 이러한 학습은 하나의 단어를 보고 다른 단어를 예측해내는 방식으로 이루어지며 이를 predictive method 방식이라 합니다.
남들과 다른 세특, 어떻게 시작할지 막막하다면?
세특 탐구 특화 아카AI로 나만의 주제 추천받으세요.